我想爬虫爬取特定的标题的bug,我想模拟禅道自带的自定义搜索功能来获取其页面,然后再提取其页面中的信息(python爬虫)
回帖数
6
阅读数
3504
发表时间
2017-08-28 15:36:55
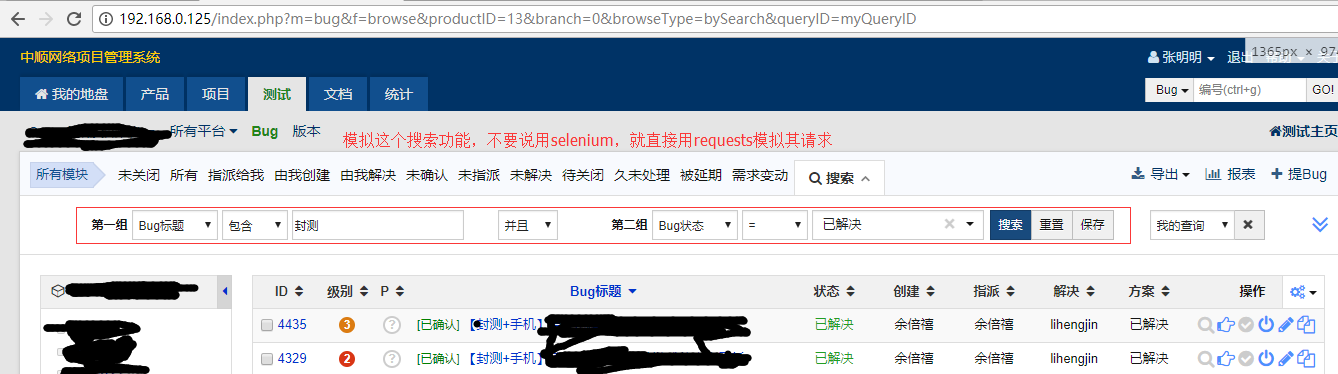
 刷新一次网页,产生了3个http请求,请求之间都是相互依赖的,求大神指点迷津
刷新一次网页,产生了3个http请求,请求之间都是相互依赖的,求大神指点迷津
 石洋洋
石洋洋
禅道中的搜索条件是记录在session中的,建议直接连接mysql库直接查询相应的数据。
2017-08-28 18:31:25 石洋洋 回帖
你好,我最近也在做这个功能,请问你解决了没有?
2020-09-18 09:44:40 廖荣玄 回帖
@ 廖荣玄:没有session是模拟不了的。
2020-09-22 13:47:56 石洋洋 回帖
原帖由
石洋洋 于
2020-09-22 13:47:56 发表
@ 廖荣玄:没有session是模拟不了的。
那我如果用session,session不进行重新更换,就每次结果都会一致么?
那您这边知道python有什么更换session的方式么?或者说清楚之前session中的内容
2020-09-24 17:13:15 廖荣玄 回帖
是的,session一样的话结果是一样的。
python这块我们没有用过不太熟悉,可能帮不太上什么忙,需要您再研究一下了。
建议您可以试试直接通过mysql进行搜索获取数据呢
2020-09-24 17:40:39 王林 回帖

联系人
魏中显/高级客户经理
电话(微信)
18561939726
QQ号码
1746749398
联系邮箱
weizhongxian@chandao.com

联系我们
魏中显
高级客户经理
电话(微信)
18561939726
QQ号码
1746749398
联系邮箱
weizhongxian@chandao.com

完善信息领取项目管理礼包
270+项目管理实践
100+项目管理视频
50+项目管理知识模版
去完善
魏中显/高级客户经理
联系客服领取礼包


