【Sora】活着已经够焦虑了,别再制造焦虑了
原创- 禅道🌻
 2024-02-21 17:30:00
2024-02-21 17:30:00  24944
24944
本篇目录
“人类要完(gg humans)。”
OpenAI全新的视频生成AI大模型Sora的发布,让各类“危言耸听”的言论甚嚣尘上。
但,活着已经够焦虑了,咱还是别制造焦虑了。
尽管Sora的发布无疑是AI领域的一个爆炸性新闻,但还是要用理性的视角看待,到底生成视频AI对我们会有怎样的影响?
一、Sora的技术实现
Sora,这个模型可以通过一段文本生成长达60秒的视频,不仅如此,视频画面也能呈现不同的角色、特定的动作还有复杂的场景。
听起来很酷,对吧?
与先前的关注短视频、固定大小的视频生成模型不同,Sora能够生成不同时长、长宽比和分辨率的视频和图像,最长可达60秒的高清视频。那Sora是怎么实现这种高质量生成效果的?这不,OpenAI很快公开了Sora的技术报告。
1、将各类视觉数据转化为patches
Sora的灵感来自于大语言模型。Sora参考大语言模型的token标记方法(将代码、数学等各种自然语言用统一的标记方法表示),采用视觉patches方法,也就是先将视频压缩到低维度的形式(具体看下文“视频压缩网络”),再把输入的图片、视频转换为多个patch,再统一进行处理。
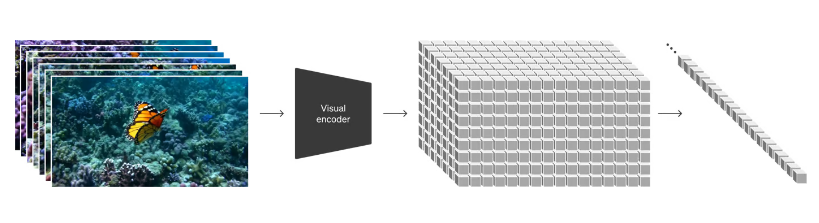
2、视频压缩网络
视频压缩网络,用于降低视觉数据的维度,从空间和时间两个维度对图片/视频进行压缩。由于Sora的训练直接在视频数据的原始尺寸上进行,所以在输出时,Sora可以hold住各种不同的分辨率、时长、宽高比、视角等的视频。因此,不同的图片和视频在用于训练时的区别仅在于patch数量的多少,而无需对视频的大小、时长进行限定、裁剪,训练端不会接收到残缺数据。
3、视频生成的缩放式Transformer
与GPT的Transformer机制稍显不同,Sora的Transformer可将接收到的patches及文本提示等信息,转换为视频内容。此外,还能扩展现有视频或补全缺失的帧,可以向前向后双向延长视频,如下图,随着训练计算的增加,样本质量得到显著提高。

4、语言理解
要想根据文本生成视频,就需要先生成大量文本字幕。因此,Sora应用了DALL-E 3(文字转图像模型)的re-captioning技术,也就是利用GPT将简短的用户提示转为较长的详细字幕,通过字幕生成器模型为视频生成文本字幕,来帮助Sora生成准确遵循用户提示的高质量视频。
二、Sora的“啊哈时刻”
1、让时间、分辨率、宽高比变化起来
过去,一些图像视频生成方法一般会将视频裁剪或修剪为标准尺寸,如分辨率是256x256的4秒视频。但打破这种固定,选择让时间、分辨率、宽高比变化起来,有几个好处:(1)采样的灵活性
Sora能采样1920x1080以及1080x1920这两个尺寸的视频以及介于两者之间的所有尺寸的视频。因此,Sora可以根据原始宽高比为不同尺寸的设备创建内容,也可以生成不同分辨率的视频内容。




(2)更优化的框架构图
下图中,第一个视频是将所有视频裁剪为正方形的模型版本生成的视频,第二个视频是Sora生成的视频。相比之下,Sora的视频的取景构图有所改善,对构图主体的呈现也较为完整。

2、通过图像和视频进行提示
Sora不仅可以实现文本到视频的转变,还可以通过已有的图片或视频来生成视频。(1)通过图像制作动画
只要提供图像和提示,Sora就能够生成视频。

(2)扩展视频
Sora能够在原视频的基础上向前或向后扩展视频。这是Sora将一段生成的视频向后拓展出的几个新视频,虽然它们的开头各不相同,但结局趋于一致。



假若用此方法不断地扩展视频,就可以实现视频的无限循环。


(3)视频间的处理
- 调整视频场景
Sora能够根据文本提示编辑图像和视频,在零样本的前提下改变视频的风格和场景。
- 视频间的无缝衔接
我们还可以利用Sora实现两个视频的无缝转场。


(视频1:无人机飞行)

(视频2:海中蝴蝶)

(视频3:视频1与2无缝衔接)
3、图像生成能力
Sora还能生成各种尺寸的高质量图像,最高分辨率可达2048x2048。下图为使用参数50毫米 f/1.2的数码单反相机,拍摄拥有舒适的小屋和北极光的雪山村庄。

4、Sora的模拟能力
Sora能够模拟现实世界中人、动物或环境的某些方面。(1)极真实的三维空间
Sora可以生成模拟动态摄像机拍摄的视频。随着摄像机的移动和旋转,人、场景等元素在三维空间中的移动非常合理。


在视频生成模型中,一个重要的挑战是确保视频的连贯性。一般情况下,Sora能够有效地捕捉短距离和长距离的依赖关系,但偶尔Sora这方面的能力也会失效。举例来说,即便人、动物或物体被遮挡或暂时离开画面,Sora也能在之后让它们重回画面。同时,如果需要给同一个角色生成多个镜头,Sora也能保持这个角色外观的一致性。


Sora有时可以用简单的方式来模拟现实世界的真实细节。例如,画家可以在画布上留下新的笔触,并随着时间的推移而持续存在,或者一个人在吃汉堡的过程中,会在汉堡上留下咬痕。


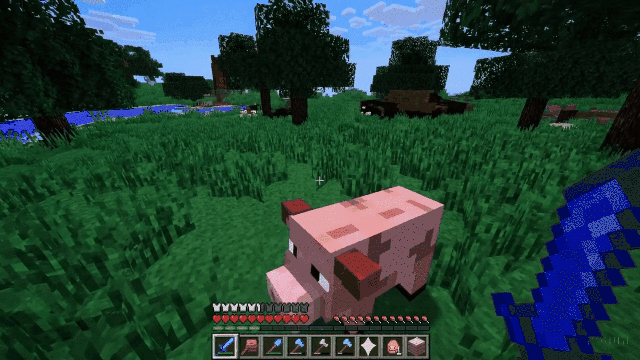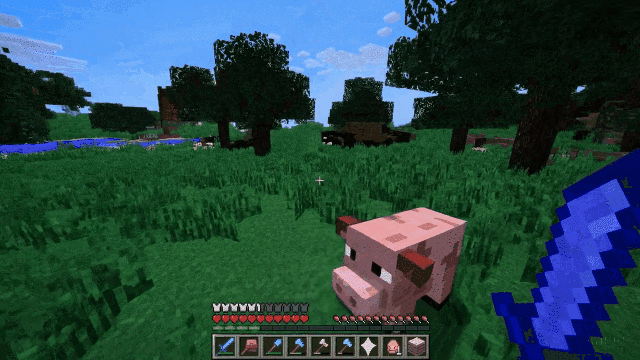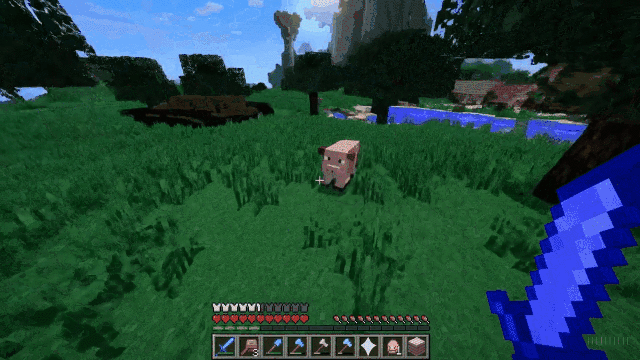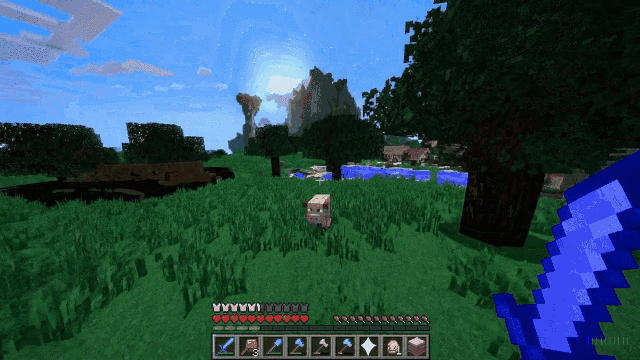
这个就更有意思了。在演示这个功能的时候,OpenAI工作人员用Minecraft(《我的世界》)游戏为例:给Sora提供包含“Minecraft”的提示,Sora便可以渲染出与这款游戏极为相似的界面显示和动态,同时这个视频还能跟随玩家视角,丝滑地转换视野画面。
三、正视Sora
我们赞叹于这些视频的活泼灵动,震惊于视频生成的精细清晰。但,不可否认的是,“世界模拟器”Sora仍有许多不可忽视的局限性:它不能准确地模拟某些相互作用的物理过程,例如玻璃破碎的瞬间;长时间样本中容易出现不连贯性或对象的自发出现等等。当然,随着技术的越来越成熟,这种局限性也会随之减少。

每次震撼人心技术的出现,最惶恐的就是打工人。或许,Sora的发布会对未来某些行业带来颠覆性的改变,但我们所能做的唯有正视Sora。
1、应用:大有所为
在应用上,以Sora为代表的AI视频生成正在帮助人们在提升效率的道路上加速前行。前段时间,UP主“AI疯人院”用AI制作了《西游记》短片,也引发了大众热议。短片作者表示,自己人工制作至少需要半年,而通过AI生成,用时一周就完成了。
(图源bilibili)
AI生成视频的技术在未来应用层面,有着更广阔的方向,会大大降低视频创作的门槛,降低高质量视频制作的难度。
2、硬伤:真实的“颠覆”
我们不得不承认,与各类AI大模型一样,Sora也存在不可避免的硬伤:比如生成内容的真实性与准确性。提及AI生成视频、AI换脸,随之而来的就是诈骗行业“技术”的升级换代,以及对用户隐私的侵犯。2024年年初,就有诈骗分子利用AI假造香港特首李家超和马斯克的视频向香港市民推介一项投资计划。而如今,Sora的问世,更是让我们常说的“眼见为实”遭到了不小的挑战。
再比如AI生成内容的固化风格,让我们也能够较为轻松地辨别“AI”与“非AI”的区别。这种“很AI”式的内容风格在应用上也稍显局限。因此,在内容创作中,目前的Sora仍无法胜任的,依然是创造性、发散性的工作。
3、行动:能力day day up
接触了各类AI工具的很多朋友都会有这样的疑问:我的AI好像不太聪明?别人的AI总是回答得很完美,我的AI总是词不达意?
我们真正想关注的是在逻辑表达能力的背后,需要基础扎实的中英文表达能力。我们想让Sora生成什么样的视频、构建哪种故事、选择什么风格以及做什么动作等等,这一切都需要我们有讲故事的能力、清晰的表达能力。当我们给它们输入的内容更详细,它们的反馈会更接近我们想要表达的内容。
另外,就是创造力、创新思维的培养。上面也有提及,目前的Sora等AI工具无法胜任创造性工作,而这恰好是我们可以重点培养的方向。在短视频时代,有的人凭借巧妙有趣的转场镜头区别于其他同领域视频制作者,有的人用鬼畜视频让“小品之王”赵本山老师再次爆火出圈……也像每年的春晚,有的语言类节目让我们眼前一亮,有的语言类节目却反响平平。其中的关键在于创意的不同。
四、写在最后
Sora模型的发布让有关“AI代替人类”的讨论更为激烈。我们该思考一个问题:AI技术的快速发展是否让我们变得太过于焦虑?人类的发展一直伴随着革命,从农业革命,到工业革命,再到信息革命,如今进入了AI革命,我们通过不断革命来促进生产力的提升。如今的很多岗位都是十几年前甚至几年前没有的,每天都有人在失业,也每天都有人在胜任新岗位。
我们无从得知未来会有什么样的岗位出现与消失。与其焦虑,我们不如利用AI技术来提升自己的竞争力,以应对未来的位置。
文章图片源于OpenAI技术报告:https://openai.com/research/video-generation-models-as-world-simulators













































推荐阅读


 春哥
春哥 
什么样的产品算是好产品?





感谢您的!为确保您能充分发挥禅道的价值,我们为您准备了以下专属服务:
 精品资料包
精品资料包立即获取《软件研发质量管理体系建设白皮书》、《PMO实践白皮书》《IPD资料》等行业最佳实践资料。
 1V1产品演示
1V1产品演示为您量身定制线上演示,深度讲解核心功能与适用场景。
 免费试用增强功能
免费试用增强功能获取正式试用授权,解锁全部功能,带领团队亲身体验。
 专属顾问答疑支持
专属顾问答疑支持在使用中遇到的任何问题,您的专属顾问将及时为您解答。
添加您的专属顾问获取服务

扫码添加领专属服务


